The nature of consciousness remains a contentious subject out there. I’m a physicalist myself — as I explain in The Big Picture and elsewhere, I think consciousness is best understood as weakly-emergent from the ordinary physical behavior of matter, without requiring any special ontological status at a fundamental level. In poetic-naturalist terms, consciousness is part of a successful way of talking about what happens at the level of humans and other organisms. “Being conscious” and “having conscious experiences” are categories that help us understand how human beings live and behave, while corresponding to goings-on at more fundamental levels in which the notion of consciousness plays no role at all. Nothing very remarkable about that — the same could be said for the categories of “being alive” or “being a table.” There is a great deal of work yet to be done to understand how consciousness actually works and relates to what happens inside the brain, but it’s the same kind of work that is required in other questions at the science/philosophy boundary, without any great metaphysical leaps required.
Not everyone agrees! I recently went on a podcast hosted by philosophers Philip Goff (former Mindscape guest) and Keith Frankish to hash it out. Philip is a panpsychist, who believes that consciousness is everywhere, underlying everything we see around us. Keith is much closer to me, but prefers to describe himself as an illusionist about consciousness.

Obviously we had a lot to disagree about, but it was a fun and productive conversation. (I’m nobody’s panpsychist, but I’m extremely impressed by Philip’s willingness and eagerness to engage with people with whom he seriously disagrees.) It’s a long video; the consciousness stuff starts around 17:30, and goes to about 2:04:20.
But despite the length, there was a point that Philip raised that I don’t think was directly addressed, at least not carefully. And it goes back to something I’m quite fond of: the Zombie Argument for Physicalism. Indeed, this was the original title of a paper that I wrote for a symposium responding to Philip’s book Galileo’s Error. But in the editing process I realized that the argument wasn’t original to me; it had appeared, in somewhat different forms, in a few previous papers:
- Balog, K. (1999). “Conceivability, Possibility, and the Mind-Body Problem,” The Philosophical Review, 108: 497-528.
- Frankish, K. (2007). “The Anti-Zombie Argument,” The Philosophical Quarterly, 57: 650-666.
- Brown, R. (2010). “Deprioritizing the A Priori Arguments against Physicalism,” Journal of Consciousness Studies, 17 (3-4): 47-69.
- Balog, K. (2012). “In Defense of the Phenomenal Concept Strategy,” Philosophy and Phenomenological Research, 84: 1-23.
- Campbell, D., J. Copeland and Z-R Deng 2017. “The Inconceivable Popularity of Conceivability Arguments,” The Philosophical Quarterly, 67: 223—240.
So the published version of my paper shifted the focus from zombies to the laws of physics.
The idea was not to explain how consciousness actually works — I don’t really have any good ideas about that. It was to emphasize a dilemma that faces anyone who is not a physicalist, someone who doesn’t accept the view of consciousness as a weakly-emergent way of talking about higher-level phenomena.
The dilemma flows from the following fact: the laws of physics underlying everyday life are completely known. They even have a name, the “Core Theory.” We don’t have a theory of everything, but what we do have is a theory that works really well in a certain restricted domain, and that domain is large enough to include everything that happens in our everyday lives, including inside ourselves. I won’t rehearse all the reasons we have for believing this is probably true, but they’re in The Big Picture, and I recently wrote a more technical paper that goes into some of the details:
Given that success, the dilemma facing the non-physicalist about consciousness is the following: either your theory of consciousness keeps the dynamics of the Core Theory intact within its domain of applicability, or it doesn’t. There aren’t any other options! I emphasize this because many non-physicalists are weirdly cagey about whether they’re going to violate the Core Theory. In our discussion, Philip suggested that one could rely on “strong emergence” to create new kinds of behavior without really violating the CT. You can’t. The fact that the CT is a local effective field theory completely rules out the possibility, for reasons I talk about in the above two papers.
That’s not to say we are certain the Core Theory is correct, even in its supposed domain of applicability. As good scientists, we should always be open to the possibility that our best current theories will be proven inadequate by future developments. It’s absolutely fine to base your theory of consciousness on the idea that the CT will be violated by consciousness itself — that’s one horn of the above dilemma. The point of “Consciousness and the Laws of Physics” was simply to emphasize the extremely high standard to which any purported modification should be held. The Core Theory is extraordinarily successful, and to violate it within its domain of applicability means not only that we are tweaking a successful model, but that we are somehow contradicting some extremely foundational principles of effective field theory. And maybe consciousness does that, but I want to know precisely how. Show me the equations, explain what happens to energy conservation and gauge invariance, etc.
Increasingly, theorists of consciousness appreciate this fact. They therefore choose the other horn of the dilemma: leave the Core Theory intact as a theory of the dynamics of what happens in the world, but propose that a straightforward physicalist understanding fails to account for the fundamental nature of the world. The equations might be right, in other words, but to account for consciousness we should posit that Mind (or something along those lines) underlies all of the stuff obeying those equations. It’s not hard to see how this strategy might lead one to a form of panpsychism.
That’s fine! You are welcome to contemplate that. But then we physicalists are welcome to tell you why it doesn’t work. That’s precisely what the Zombie Argument for Physicalism does. It’s not precisely an argument for physicalism tout court, but for the superiority of physicalism over a non-physicalist view that purports to explain consciousness while leaving the behavior of matter unaltered.
Usually, of course, the zombie argument is deployed against physicalism, not for it. I know that. We find ourselves in the presence of irony.
The intuition behind the usual zombie argument stems from a conviction from introspection — from our first-person experience of the world, inaccessible in principle to outsiders — that there is something going on other than the mere physical behavior of physical stuff. And if that’s true, we can imagine the same behavior of physical stuff with or without consciousness. A (philosophical) zombie is a creature that behaves exactly as an ordinary person would in every way, but lacks the inner experience of consciousness — the qualia that characterize “what it is like” to be something. The argument is then that, if we can conceive of precisely the same physical behavior with and without consciousness, consciousness must be something other than a way of talking about physical behavior. It’s a bit reminiscent of Descartes’s argument for mind-body dualism: I can imagine my body not existing, but I can’t imagine my mind not existing, so the mind and body must be different things. But the conclusion here is not supposed to be that the mind must be a distinct substance from the body, merely the somewhat weaker conclusion that our conscious experiences cannot be reduced to the behavior of physical matter.
Let me stress the radicalness of the zombie concept, because I think people sometimes underestimate it, even some proponents of the usual zombie argument. When first presented with the idea of a philosophical zombie, it is natural to conjure up something like a Vulcan from Star Trek: humanoid in appearance, rational, and indisputably alive, but lacking some kind of affect or emotion. That is not right. The zombie, to reiterate, behaves exactly as a conscious creature would behave. If you interacted with a zombie, it would exhibit all the features of love and joy and sadness and anxiety that an ordinary person would. Zombies would cry of heartbreak, compose happy songs, giggle while rolling around on the ground with puppies, and write densely-argued books against the idea that consciousness could be entirely physical. If you asked a zombie about its inner conscious experiences, it would earnestly assure you that it had them, and would describe “what it was like” to experience this or that, on the basis of its introspection. The difference is that, unlike conscious creatures who are purportedly accurate when they make those claims, the zombie is wrong. You would never be able to convince the zombie they were wrong, but too bad for them.
Nobody is claiming the zombies actually exist or even are possible in our world, only that they are conceivable. And that if we can conceive of them, our notion of “consciousness” must be distinct from our notion of the behavior of matter.
But if there is an intuition that our conscious experience is something more than the motion of physical stuff, there is also a countervailing intuition: surely my consciousness affects my behavior! To a person on the street, rather than a highly-trained philosopher, it’s pretty obvious that your conscious experiences have some effect on your behavior. Such intuitions aren’t really reliable — a lot of people are intuitive dualists about the mind. But they provide pointers for us to dig into an issue and understand it better.
Taking a cue from our intuition that consciousness surely affects our behavior, and a suspicion that zombie advocates aren’t really thinking through the implications of the thought experiment, leads us to flip the usual argument on its head. The zombie scenario is actually a really good argument for physicalism (at least by contrast to the kind of passive panpsychism that doesn’t affect physical behavior in any way).
To make things clear, consider a very explicit version of the zombie scenario. We imagine two possible worlds (or at least conceivable, or at least maybe-conceivable). We have P-world (for “physical”), which consists solely of physical stuff, and that stuff obeys the Core Theory in its claimed domain of applicability. Then we have Ψ-world (for “psychist”), which behaves in precisely the same way, but which is fundamentally based on consciousness. The physical properties and behavior of Ψ-world should be thought of as aspects (emanations? not sure what the preferred vocabulary is here) of an underlying mentality.
(Note our use of “behavior” here means all of the behavior of all physical stuff, down to individual electrons and photons; not just the macroscopic behavior of human beings. There’s no connection to “behaviorism” in psychology.)
The starting point of the zombie argument for physicalism is that, when we sit down to compare P-world and Ψ-world, we realize that the purported “consciousness” that is central to Ψ-world is playing no explanatory role whatsoever. It might be there, ineffably in the background, but it has no impact at all on what human beings do or say. As Keith put it in our conversation, it offers no “differential” explanatory power to discriminate between the two scenarios.
And — here is an important point — whatever that background, causally-inert stuff is, it’s not what I have in mind when I’m trying to explain “consciousness.” The consciousness I have in mind absolutely does play an explanatory role in accounting for human behavior. The fact that someone is conscious of some inner experience (falling in love, or having the feeling they are being watched) manifestly affects their behavior. So the consciousness of Ψ-world isn’t the consciousness I care about, and I might as well be a physicalist.
Aha, says the panpsychist, but you’re leaving out something important. The behavior of which you speak can be seen by the outside world. But I also, personally, have access to my inner experience: the first-person perspective that cannot be witnessed by outsiders. Science is used to explaining objective third-person-observable behavior, but not this. I therefore have a reason — based on data, even if it’s not publicly-available — to prefer Ψ-world over P-world.
That move doesn’t work, as we can see if we think a bit more carefully about what’s going on in Ψ-world. How should I interpret someone’s claim that they have inner conscious experiences of the kind a zombie wouldn’t have? The claim itself — the utterance “I have conscious experience” — is a behavior. They said it, or wrote it, or whatever. The matter in their bodies acts in certain ways so as to form those words. And that matter, within either P-world or Ψ-world, exactly obeys the equations of motion of the Core Theory. That theory, in turn, is causally closed: you tell me the initial conditions, there is an equation that unambiguously describes how the universe evolves forward in time.
So the utterance claiming that a person has inner conscious experiences has precisely the same causal precursors in either P-world or Ψ-world: a certain configuration of particles and forces in the person’s brain and body. But we’ve agreed that non-physical consciousness plays no role in explaining those things within the context of P-world. Therefore, consciousness cannot play any role in explaining those utterances in Ψ-world, either.
Thus: you are welcome to claim that you have access to inner first-person experiences of some non-physical conscious experiences, but that claim bears no relationship whatsoever to whether or not you actually do have such experiences. So there is no “data” at all, in the ordinary sense.
Said another way: the claim is that we have a certain kind of knowledge based on introspection. But a zombie would make exactly the same claim, and you are arguing that the zombie is wrong. The lesson is that this kind of introspection is completely unreliable. And therefore there is no reason to favor Ψ-world over P-world. (The point is not that introspection itself is completely unreliable, just that if you think zombies are conceivable, you have to admit that introspection gives us no evidence for the non-physical nature of consciousness.)
Of course philosophers are very clever people, and they can invent different categories of “introspection” and “experience” and “evidence” in an attempt to make it all work out. But the essential point is clear and robust: by sequestering off “consciousness” from playing any causal role in the world, you’ve turned it into something very different from what we were originally trying to explain. Time to turn to some other strategy.
There is one dangling thread here, which is what Philip brought up in the conversation and I don’t think we did justice to. Sure, you might say, there is no differential explanatory role being played by consciousness in the comparison between P-world and Ψ-world. They both behave in the same way, even though one has consciousness and the other doesn’t. But that doesn’t mean there is no explanatory role being played within Ψ-world itself. In other words, maybe consciousness doesn’t distinguish between what happens in the two worlds, but surely it is crucial to Ψ-world considered by its own lights. That world is literally made of consciousness!
Nice try, but this move also fails. Consider an analogy: two identical coffee cups sitting on two tables. The tables themselves are identical in form, except that one table is made of wood and the other of iron. You can’t distinguish between the two worlds just by the fact that the coffee cup is being held up by the two tables (analogous to the behavior of matter in P-world and Ψ-world); in either case, the table holds up the up, despite them being made of different materials. But surely the iron is playing a role in the world where that’s what the table is made of!
Well, yes, the iron is “playing a role.” But it’s not a role that is relevant to understanding what keeps the cup from falling. If you had a “hard problem of coffee cups,” which involved understanding why cups sit peacefully on a table rather than falling to the ground, nobody would think that a table made of iron provided a better solution than a table made of wood. The explanation is material-independent. It’s the table-ness that matters, not the substance of which the table is made.
The actual analogy that Philip used in a post-discussion Twitter thread was to software, and the substrate-independence of computer algorithms.
The same response applies here. Sure, you could run the same software on different hardware. But the entire point of substrate independence is that you cannot then say that the nature of the substrate influenced the outcome of the calculation in any way! Analogously, the panpsychist who wants to differentiate between the software of reality running on physical vs. mental hardware cannot claim that consciousness gets any credit at all for our behavior in the world.
I get why non-physicalists about consciousness are reluctant to propose explicit ways in which the dynamics of the Core Theory might be violated. Physics is really strong, very well-understood, and backed by enormous piles of experimental data. It’s hard to mess with that. But the alternative of retreating to a view where consciousness “explains” things in the world, while exhibiting precisely the same behaviors that the world would have if there were no consciousness, pretty clearly fails. It’s better to be a physicalist who works to understand consciousness as a higher-level description of ordinary physical stuff doing its ordinary physical things. If you’re not willing to go there, face up to the challenge and explain exactly how our physical understanding needs to be modified. You’ll probably be wrong, but if you turn out to be right, it will all be worth it. That’s how science goes.
]]>


 . In classical mechanics, there is a lowest-energy state where the particle just sits at the bottom of its potential, unmoving, so both its kinetic and potential energies are zero. We can give it any positive amount of energy we like, either by kicking it to impart motion or just picking it up and dropping it in the potential at some point other than the origin.
. In classical mechanics, there is a lowest-energy state where the particle just sits at the bottom of its potential, unmoving, so both its kinetic and potential energies are zero. We can give it any positive amount of energy we like, either by kicking it to impart motion or just picking it up and dropping it in the potential at some point other than the origin. . Nothing discrete about that; it’s a fundamentally smooth function. But second, that function isn’t arbitrary; it’s going to obey the
. Nothing discrete about that; it’s a fundamentally smooth function. But second, that function isn’t arbitrary; it’s going to obey the  we like. Still nothing discrete there. But there is one requirement, coming from the idea of boundary conditions: if the wave function grows (or remains constant) as
we like. Still nothing discrete there. But there is one requirement, coming from the idea of boundary conditions: if the wave function grows (or remains constant) as  , the potential energy grows along with it. (It actually has to diminish at infinity just to be a wave function at all, but for the moment let’s think about the energy.) When we bring in the fourth ingredient, “what we care about,” the answer is that we care about low-energy states of the oscillator. That’s because in real-world situations, there is dissipation. Whatever physical system is being modeled by the harmonic oscillator, in reality it will most likely have friction or be able to give off photons or something like that. So no matter where we start, left to its own devices the oscillator will diminish in energy. So we generally care about states with relatively low energy.
, the potential energy grows along with it. (It actually has to diminish at infinity just to be a wave function at all, but for the moment let’s think about the energy.) When we bring in the fourth ingredient, “what we care about,” the answer is that we care about low-energy states of the oscillator. That’s because in real-world situations, there is dissipation. Whatever physical system is being modeled by the harmonic oscillator, in reality it will most likely have friction or be able to give off photons or something like that. So no matter where we start, left to its own devices the oscillator will diminish in energy. So we generally care about states with relatively low energy.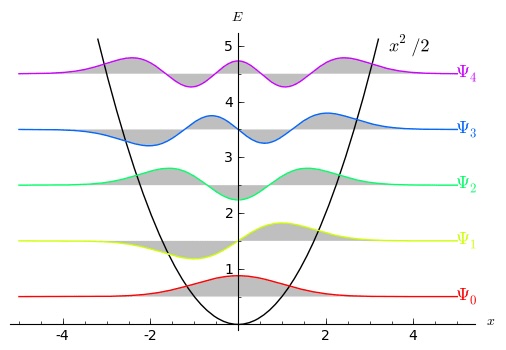
 as possible” and “not changing too rapidly at any point.” That compromise looks like the bottom (red) curve in the figure: starts at zero on the left, gradually increases and then decreases as it continues on to the right. It is a feature of eigenstates that they are all “orthogonal” to each other — there is zero net overlap between them. (Technically, if you multiply them together and integrate over
as possible” and “not changing too rapidly at any point.” That compromise looks like the bottom (red) curve in the figure: starts at zero on the left, gradually increases and then decreases as it continues on to the right. It is a feature of eigenstates that they are all “orthogonal” to each other — there is zero net overlap between them. (Technically, if you multiply them together and integrate over  , the answer is zero.) So the next eigenstate will first oscillate down, then up, then back to zero. Subsequent energy eigenstates will each oscillate just a bit more, so they contain the least possible energy while being orthogonal to all the lower-lying states. Those requirements mean that they will each pass through zero exactly one more time than the state just below them.
, the answer is zero.) So the next eigenstate will first oscillate down, then up, then back to zero. Subsequent energy eigenstates will each oscillate just a bit more, so they contain the least possible energy while being orthogonal to all the lower-lying states. Those requirements mean that they will each pass through zero exactly one more time than the state just below them.



 ” and “spin-down” or “
” and “spin-down” or “ .” But before we’ve made the measurement, the system can be in some superposition of both possibilities. We would write
.” But before we’ve made the measurement, the system can be in some superposition of both possibilities. We would write  , the wave function of the spin, as
, the wave function of the spin, as![\[ (\Psi) = a(\uparrow) + b(\downarrow), \]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-99680f4c2d2711403d8013da6c15e01f_l3.png "Rendered by QuickLaTeX.com")
 and
and  are numerical coefficients, the “amplitudes” corresponding to spin-up and spin-down, respectively. (They will generally be complex numbers, but we don’t have to worry about that.)
are numerical coefficients, the “amplitudes” corresponding to spin-up and spin-down, respectively. (They will generally be complex numbers, but we don’t have to worry about that.)![\[ (\Psi)_\mathrm{post-measurement} = \begin{cases} (\uparrow), & \mbox{with probability } |a|^2,\\ (\downarrow), & \mbox{with probability } |b|^2. \end{cases}\]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-8107a4b9ad0ecdf4d1c5352831392591_l3.png "Rendered by QuickLaTeX.com")
 to any particular quantum state, even if specific measurements might give answers that fluctuate around that central value. (For experts: the expectation value of the Hamiltonian.) If we think of an arbitrary quantum state as a weighted superposition of various specific-energy eigenstates, the average energy is just what it sounds like: the weighted average of the energies of all those eigenstates.
to any particular quantum state, even if specific measurements might give answers that fluctuate around that central value. (For experts: the expectation value of the Hamiltonian.) If we think of an arbitrary quantum state as a weighted superposition of various specific-energy eigenstates, the average energy is just what it sounds like: the weighted average of the energies of all those eigenstates. , and the spin-down state has a definite energy
, and the spin-down state has a definite energy  . Then the average energy is just a combination of both these values, weighted by the squares of the amplitudes:
. Then the average energy is just a combination of both these values, weighted by the squares of the amplitudes:![\[ \bar{E} = |a|^2E_\uparrow + |b|^2 E_\downarrow.\]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-5fc68edfbcd29b175a5d7a90f1601ce1_l3.png "Rendered by QuickLaTeX.com")
 , with amplitudes
, with amplitudes  and average energies
and average energies  , the average energy of the whole shebang is
, the average energy of the whole shebang is![\[\bar{E} = |a_1|^2E_1 + |a_2|^2E_2 + \cdots.\]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-402a83b1f1362789079af46a185e285a_l3.png "Rendered by QuickLaTeX.com")
 , and those numbers go down over time as branches split. The effects precisely cancel, so that the total energy of the universe (all branches included) is constant. It’s just that individual branches get “thinner” over time (their amplitudes get smaller), so they make smaller and smaller contributions to the total.
, and those numbers go down over time as branches split. The effects precisely cancel, so that the total energy of the universe (all branches included) is constant. It’s just that individual branches get “thinner” over time (their amplitudes get smaller), so they make smaller and smaller contributions to the total.
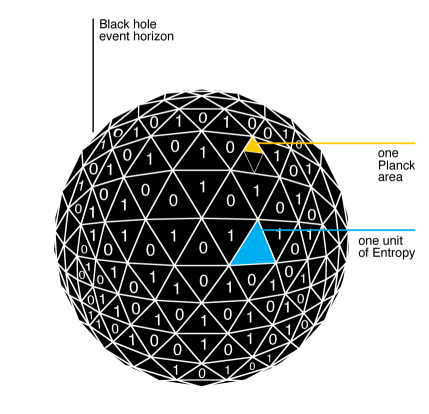
 . Then its Bekenstein-Hawking entropy is
. Then its Bekenstein-Hawking entropy is ![\[S_\mathrm{BH} = \frac{c^3}{4G\hbar}A,\]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-e00278f91c29d53663b438ba10d89895_l3.png "Rendered by QuickLaTeX.com")
 is the speed of light,
is the speed of light,  is Newton’s constant of gravitation, and
is Newton’s constant of gravitation, and  is Planck’s constant of quantum mechanics. A simple formula, but already intriguing, as it seems to combine relativity (
is Planck’s constant of quantum mechanics. A simple formula, but already intriguing, as it seems to combine relativity (