This year we give thanks for an area of mathematics that has become completely indispensable to modern theoretical physics: Riemannian Geometry. (We’ve previously given thanks for the Standard Model Lagrangian, Hubble’s Law, the Spin-Statistics Theorem, conservation of momentum, effective field theory, the error bar, gauge symmetry, Landauer’s Principle, and the Fourier Transform. Ten years of giving thanks!)
Now, the thing everyone has been giving thanks for over the last few days is Albert Einstein’s general theory of relativity, which by some measures was introduced to the world exactly one hundred years ago yesterday. But we don’t want to be everybody, and besides we’re a day late. So it makes sense to honor the epochal advance in mathematics that directly enabled Einstein’s epochal advance in our understanding of spacetime.
Highly popularized accounts of the history of non-Euclidean geometry often give short shrift to Riemann, for reasons I don’t quite understand. You know the basic story: Euclid showed that geometry could be axiomatized on the basis of a few simple postulates, but one of them (the infamous Fifth Postulate) seemed just a bit less natural than the others. That’s the parallel postulate, which has been employed by generations of high-school geometry teachers to torture their students by challenging them to “prove” it. (Mine did, anyway.)
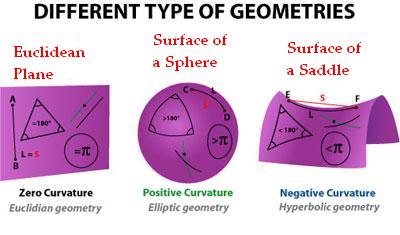
It can’t be proved, and indeed it’s not even necessarily true. In the ordinary flat geometry of a tabletop, initially parallel lines remain parallel forever, and Euclidean geometry is the name of the game. But we can imagine surfaces on which initially parallel lines diverge, such as a saddle, or ones on which they begin to come together, such as a sphere. In those contexts it is appropriate to replace the parallel postulate with something else, and we end up with non-Euclidean geometry.
Historically, this was first carried out by Hungarian mathematician János Bolyai and the Russian mathematician Nikolai Lobachevsky, both of whom developed the hyperbolic (saddle-shaped) form of the alternative theory. Actually, while Bolyai and Lobachevsky were the first to publish, much of the theory had previously been worked out by the great Carl Friedrich Gauss, who was an incredibly influential mathematician but not very good about getting his results into print.
The new geometry developed by Bolyai and Lobachevsky described what we would now call “spaces of constant negative curvature.” Such a space is curved, but in precisely the same way at every point; there is no difference between what’s happening at one point in the space and what’s happening anywhere else, just as had been the case for Euclid’s tabletop geometry.
Real geometries, as takes only a moment to visualize, can be a lot more complicated than that. Surfaces or solids can twist and turn in all sorts of ways. Gauss thought about how to deal with this problem, and came up with some techniques that could characterize a two-dimensional curved surface embedded in a three-dimensional Euclidean space. Which is pretty great, but falls far short of the full generality that mathematicians are known to crave.
 Fortunately Gauss had a brilliant and accomplished apprentice: his student Bernard Riemann. (Riemann was supposed to be studying theology, but he became entranced by one of Gauss’s lectures, and never looked back.) In 1853, Riemann was coming up for Habilitation, a German degree that is even higher than the Ph.D. He suggested a number of possible dissertation topics to his advisor Gauss, who (so the story goes) chose the one that Riemann thought was the most boring: the foundations of geometry. The next year, he presented his paper, “On the hypotheses which underlie geometry,” which laid out what we now call Riemannian geometry.
Fortunately Gauss had a brilliant and accomplished apprentice: his student Bernard Riemann. (Riemann was supposed to be studying theology, but he became entranced by one of Gauss’s lectures, and never looked back.) In 1853, Riemann was coming up for Habilitation, a German degree that is even higher than the Ph.D. He suggested a number of possible dissertation topics to his advisor Gauss, who (so the story goes) chose the one that Riemann thought was the most boring: the foundations of geometry. The next year, he presented his paper, “On the hypotheses which underlie geometry,” which laid out what we now call Riemannian geometry.
With this one paper on a subject he professed not to be all that interested in, Riemann (who also made incredible contributions to analysis and number theory) provided everything you need to understand the geometry of a space of arbitrary numbers of dimensions, with an arbitrary amount of curvature at any point in the space. It was as if Bolyai and Lobachevsky had invented the abacus, Gauss came up with the pocket calculator, and Riemann had turned around a built a powerful supercomputer.
Like many great works of mathematics, a lot of new superstructure had to be built up along the way. A subtle but brilliant part of Riemann’s work is that he didn’t start with a larger space (like the three-dimensional almost-Euclidean world around us) and imagine smaller spaces embedded with it. Rather, he considered the intrinsic geometry of a space, or how it would look “from the inside,” whether or not there was any larger space at all.
Next, Riemann needed a tool to handle a simple but frustrating fact of life: “curvature” is not a single number, but a way of characterizing many questions one could possibly ask about the geometry of a space. What you need, really, are tensors, which gather a set of numbers together in one elegant mathematical package. Tensor analysis as such didn’t really exist at the time, not being fully developed until 1890, but Riemann was able to use some bits and pieces of the theory that had been developed by Gauss.
Finally and most importantly, Riemann grasped that all the facts about the geometry of a space could be encoded in a simple quantity: the distance along any curve we might want to draw through the space. He showed how that distance could be written in terms of a special tensor, called the metric. You give me segment along a curve inside the space you’re interested in, the metric lets me calculate how long it is. This simple object, Riemann showed, could ultimately be used to answer any query you might have about the shape of a space — the length of curves, of course, but also the area of surfaces and volume of regions, the shortest-distance path between two fixed points, where you go if you keep marching “forward” in the space, the sum of the angles inside a triangle, and so on.
Unfortunately, the geometric information implied by the metric is only revealed when you follow how the metric changes along a curve or on some surface. What Riemann wanted was a single tensor that would tell you everything you needed to know about the curvature at each point in its own right, without having to consider curves or surfaces. So he showed how that could be done, by taking appropriate derivatives of the metric, giving us what we now call the Riemann curvature tensor. Here is the formula for it:
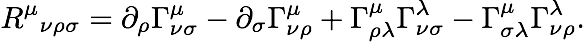
This isn’t the place to explain the whole thing, but I can recommend some spiffy lecture notes, including a very short version, or the longer and sexier textbook. From this he deduced several interesting features about curvature. For example, the intrinsic curvature of a one-dimensional space (a line or curve) is alway precisely zero. Its extrinsic curvature — how it is embedded in some larger space — can be complicated, but to a tiny one-dimensional being, all spaces have the same geometry. For two-dimensional spaces there is a single function that characterizes the curvature at each point; in three dimensions you need six numbers, in four you need twenty, and it goes up from there.
There were more developments in store for Riemannian geometry, of course, associated with names that are attached to various tensors and related symbols: Christoffel, Ricci, Levi-Civita, Cartan. But to a remarkable degree, when Albert Einstein needed the right mathematics to describe his new idea of dynamical spacetime, Riemann had bequeathed it to him in a plug-and-play form. Add the word “time” everywhere we’ve said “space,” introduce some annoying minus signs because time and space really aren’t precisely equivalent, and otherwise the geometry that Riemann invented is the same we use today to describe how the universe works.
Riemann died of tuberculosis before he reached the age of forty. He didn’t do bad for such a young guy; you know you’ve made it when you not only have a Wikipedia page for yourself, but a separate (long) Wikipedia page for the list of things named after you. We can all be thankful that Riemann’s genius allowed him to grasp the tricky geometry of curved spaces several decades before Einstein would put it to use in the most beautiful physical theory ever invented.




 .
.

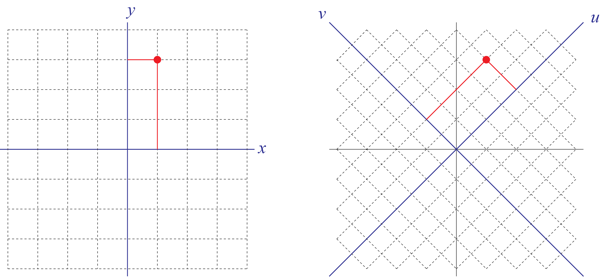
 One of the things Kip talks about is that the film refers to the concept of a tesseract, which he thought was fun. A tesseract is a four-dimensional version of a cube; you can’t draw it faithfully in two dimensions, but with a little imagination you can get the idea from the picture on the right. Kip mentions that he first heard of the concept of a tesseract in George Gamow’s classic book
One of the things Kip talks about is that the film refers to the concept of a tesseract, which he thought was fun. A tesseract is a four-dimensional version of a cube; you can’t draw it faithfully in two dimensions, but with a little imagination you can get the idea from the picture on the right. Kip mentions that he first heard of the concept of a tesseract in George Gamow’s classic book 
