(Apologies for the ugly blog format. We had a bit of a crash, and are working to get the template back in working order.)
This year we give thanks for a crucially important idea that can mean very different things to different people: information. (We’ve previously given thanks for the Standard Model Lagrangian, Hubble’s Law, the Spin-Statistics Theorem, conservation of momentum, effective field theory, the error bar, gauge symmetry, Landauer’s Principle, the Fourier Transform, Riemannian Geometry, the speed of light, the Jarzynski equality, the moons of Jupiter, space, black hole entropy, electromagnetism, Arrow’s Impossibility Theorem, and quanta.)
“Information” is an idea that is everywhere in science and technology these days. From one angle it looks like such an obvious idea that it’s a bit startling to realize that information theory didn’t really come along until the work of Claude Shannon in the 1940s. From another, the idea has so many different shades of meaning that we shouldn’t be surprised (that’s a joke you will get in a bit) that it can be hard to understand.
Information theory is obviously an enormous subject, but we’re just giving thanks, not writing a textbook. I want to mention two ideas I find especially central. First, Shannon’s idea about relating information content to “surprisal.” Second, the very different intuitive notions of information that we get from engineering and physics.
Shannon, working at Bell Labs, was interested in the problem of how to send trustworthy signals efficiently over transatlantic cables. He was thinking about various ways to express information in a code: a set of symbols, each with a defined meaning. So a code might be an alphabet, or a set of words, or a literal cipher. And he noticed that there was a lot of redundancy in natural languages; the word “the” appears much more often in English than the word “axe,” although both have the same number of letters.
Let’s refer to each letter or symbol in a code as an “event.” Shannon’s insight was to realize that the more unlikely an event, the more information it conveyed when it was received. The statements “The Sun rose in the east this morning” and “The Sun rose in the west this morning” contain the same number of letters, but the former contains almost no information — you already were pretty sure the Sun would be rising in the east. But the latter, if obtained from a reliable source, would be very informative indeed, precisely because it was so unexpected. Clearly some kind of unprecedented astronomical catastrophe was in progress.
Imagine we can assign a probability  to every different event
to every different event  . Shannon wanted a way to quantify the information content of that event, which would satisfy various reasonable-seeming axioms: most crucially, that the information content of two independent events is the sum of the individual information contents. But the joint probability of two events is the product of their individual probabilities. So the natural thing to do would be to define the information content as the logarithm of the probability; the logarithm of a product equals the sum of the individual logarithms. But you want low probability to correspond to high information content, so Shannon defined the information content (also called the self-information, or surprisal, or Shannon information) of an event to be minus the log of the probability, which by math is equal to the log of the reciprocal of the probability:
. Shannon wanted a way to quantify the information content of that event, which would satisfy various reasonable-seeming axioms: most crucially, that the information content of two independent events is the sum of the individual information contents. But the joint probability of two events is the product of their individual probabilities. So the natural thing to do would be to define the information content as the logarithm of the probability; the logarithm of a product equals the sum of the individual logarithms. But you want low probability to correspond to high information content, so Shannon defined the information content (also called the self-information, or surprisal, or Shannon information) of an event to be minus the log of the probability, which by math is equal to the log of the reciprocal of the probability:
![\[I(x) = - \log [p(x)] =\log \left(\frac{1}{p(x)}\right).\]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-8bcea26296a528f55b4af9871d5a4f3d_l3.png "Rendered by QuickLaTeX.com")
Note that probabilities are numbers between 0 and 1, and the log of such a number will be negative, with numbers closer to 0 being more negative than numbers closer to 1. So  goes from
goes from  at
at  to
to  at
at  . An impossible message is infinitely surprising, and therefore conveys infinite information; an inevitable message is completely unsurprising, and conveys no information at all.
. An impossible message is infinitely surprising, and therefore conveys infinite information; an inevitable message is completely unsurprising, and conveys no information at all.
From there, Shannon suggested that we could characterize how efficient an entire code was at conveying information: just calculate the average (expectation value) of the information content for all possible events. When we have a probability distribution , the average of any function  is just the sum of the the values of the function times their respective probabilities,
is just the sum of the the values of the function times their respective probabilities,  . So we characterize the information content of a code via the quantity
. So we characterize the information content of a code via the quantity
![\[H[p] = - \sum_x p(x) \log[p(x)].\]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-a01e303130437d1d62fdc7650e81d112_l3.png "Rendered by QuickLaTeX.com")
The only question is, what to call this lovely newly-defined quantity that surely nobody had ever thought of before? Happily Shannon was friends with John von Neumann, who informed him, “You should call it entropy, for two reasons. In the first place your uncertainty function has been used in statistical mechanics under that name, so it already has a name. In the second place, and more important, no one really knows what entropy really is, so in a debate you will always have the advantage.” So entropy it is.
Indeed, this formula is precisely that which had been put forward (unknown to Shannon) by Josiah Willard Gibbs in the 1870’s as a definition of entropy in statistical mechanics. (It is related to the definition on Ludwig Boltzmann’s tombstone,  , and Boltzmann had also suggested similar expressions to the above.) On the one hand, it seems remarkable to find precisely the same expression playing central roles in problems as disparate as sending signals across cables and watching cream mix into coffee; on the other hand, it’s a relatively simple expression and the axioms used to derive it are actually pretty similar, so perhaps we shouldn’t be surprised; on the third hand, the connection between information theory and statistical mechanics turns out to be deep and fruitful, so it’s more than just a mathematical coincidence.
, and Boltzmann had also suggested similar expressions to the above.) On the one hand, it seems remarkable to find precisely the same expression playing central roles in problems as disparate as sending signals across cables and watching cream mix into coffee; on the other hand, it’s a relatively simple expression and the axioms used to derive it are actually pretty similar, so perhaps we shouldn’t be surprised; on the third hand, the connection between information theory and statistical mechanics turns out to be deep and fruitful, so it’s more than just a mathematical coincidence.
But let me highlight the one aspect of the term “information” that can be sometimes confusing to people. To the engineer, a code that is maximally informative is one for which is relatively uniform over all events , which means ![H[p(x)]](https://www.preposterousuniverse.com/blog/wp-content/ql-cache/quicklatex.com-af1f25653f8a756a19c3ea1150c7a626_l3.png "Rendered by QuickLaTeX.com") is maximal or close to it; in that case, every event will tell you something at least a little bit interesting. For them, high entropy = high information.
is maximal or close to it; in that case, every event will tell you something at least a little bit interesting. For them, high entropy = high information.

But to a physicist who might be asking “how much information do I have about the state of a system?”, you have more information when is relatively narrowly concentrated around some value, rather than being all spread out. For them, high entropy = low information! Indeed, one physically-relevant notion of “information” is the “accessible information” of a system, which can be defined as  . (I talk about this a bit in my recent solo podcast on complexity.)
. (I talk about this a bit in my recent solo podcast on complexity.)

Perhaps we shouldn’t be so surprised that physicists and engineers posit oppositely-directed relationships between entropy and information. It’s just a reflection of the fact that “information” is so ubiquitous and has so many different uses. We should be thankful that we’re beginning to understand it so well.



 . In classical mechanics, there is a lowest-energy state where the particle just sits at the bottom of its potential, unmoving, so both its kinetic and potential energies are zero. We can give it any positive amount of energy we like, either by kicking it to impart motion or just picking it up and dropping it in the potential at some point other than the origin.
. In classical mechanics, there is a lowest-energy state where the particle just sits at the bottom of its potential, unmoving, so both its kinetic and potential energies are zero. We can give it any positive amount of energy we like, either by kicking it to impart motion or just picking it up and dropping it in the potential at some point other than the origin. . Nothing discrete about that; it’s a fundamentally smooth function. But second, that function isn’t arbitrary; it’s going to obey the
. Nothing discrete about that; it’s a fundamentally smooth function. But second, that function isn’t arbitrary; it’s going to obey the  we like. Still nothing discrete there. But there is one requirement, coming from the idea of boundary conditions: if the wave function grows (or remains constant) as
we like. Still nothing discrete there. But there is one requirement, coming from the idea of boundary conditions: if the wave function grows (or remains constant) as  , the potential energy grows along with it. (It actually has to diminish at infinity just to be a wave function at all, but for the moment let’s think about the energy.) When we bring in the fourth ingredient, “what we care about,” the answer is that we care about low-energy states of the oscillator. That’s because in real-world situations, there is dissipation. Whatever physical system is being modeled by the harmonic oscillator, in reality it will most likely have friction or be able to give off photons or something like that. So no matter where we start, left to its own devices the oscillator will diminish in energy. So we generally care about states with relatively low energy.
, the potential energy grows along with it. (It actually has to diminish at infinity just to be a wave function at all, but for the moment let’s think about the energy.) When we bring in the fourth ingredient, “what we care about,” the answer is that we care about low-energy states of the oscillator. That’s because in real-world situations, there is dissipation. Whatever physical system is being modeled by the harmonic oscillator, in reality it will most likely have friction or be able to give off photons or something like that. So no matter where we start, left to its own devices the oscillator will diminish in energy. So we generally care about states with relatively low energy.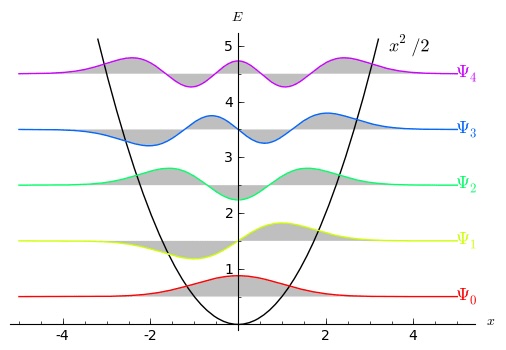
 as possible” and “not changing too rapidly at any point.” That compromise looks like the bottom (red) curve in the figure: starts at zero on the left, gradually increases and then decreases as it continues on to the right. It is a feature of eigenstates that they are all “orthogonal” to each other — there is zero net overlap between them. (Technically, if you multiply them together and integrate over
as possible” and “not changing too rapidly at any point.” That compromise looks like the bottom (red) curve in the figure: starts at zero on the left, gradually increases and then decreases as it continues on to the right. It is a feature of eigenstates that they are all “orthogonal” to each other — there is zero net overlap between them. (Technically, if you multiply them together and integrate over